[ResNet50] 전이 학습 기법을 이용한 CNN 이미지 분류 모델 생성
저번에 공부했던 ResNet 이론을 실습으로 옮겨 PyTorch 환경에서 ResNet50 사전학습 모델을 불러와
STL10 데이터셋을 전이학습시키고, 이미지 분류를 할 수 있는 모델을 생성해보자.
데이터셋 설명 및 준비에 앞서, 데이터 증강에 대해 간단히 알아보자.
데이터 증강(Data Augmentation)이란, 갖고 있는 데이터셋을 여러가지 방법으로 증강시켜
실질적인 학습 데이터셋의 규모를 키우는 방법이다.
데이터가 다양하게 많아진다는것은 학습 성능을 향상시키고 과적합을 줄일 수 있다는 것을 의미하기 때문에
데이터셋 규모가 작을때 데이터 증강은 어쩌면 필수라고 할 수 있다.

조금 더 쉽게 설명하면 위 사진에서, 원본 데이터를 d라고 하고 증강된 데이터를 Aug_d 라고 하자.
빨간색 x 표시가 Prediction일때, d만 있을때는 예측하지 못할 값들이 원본 데이터의 핵심 Feature에서
크게 벗어나지 않은 Augmented Data의 학습을 통해 적중률을 향상시킬 수 있게 되는 것이다.
STL10 데이터셋은 10개의 클래스에 대한 96 x 96의 크기 이미지로 이루어져 있는 데이터셋이다.
일반적인 객체들에 대한 데이터셋이며 Train Dataset과 Test Dataset을 제공한다.

별도의 Validation 데이터셋은 제공하지 않기 때문에 지도학습을 위해 Train Dataset에서 일부 분리하여 사용한다.
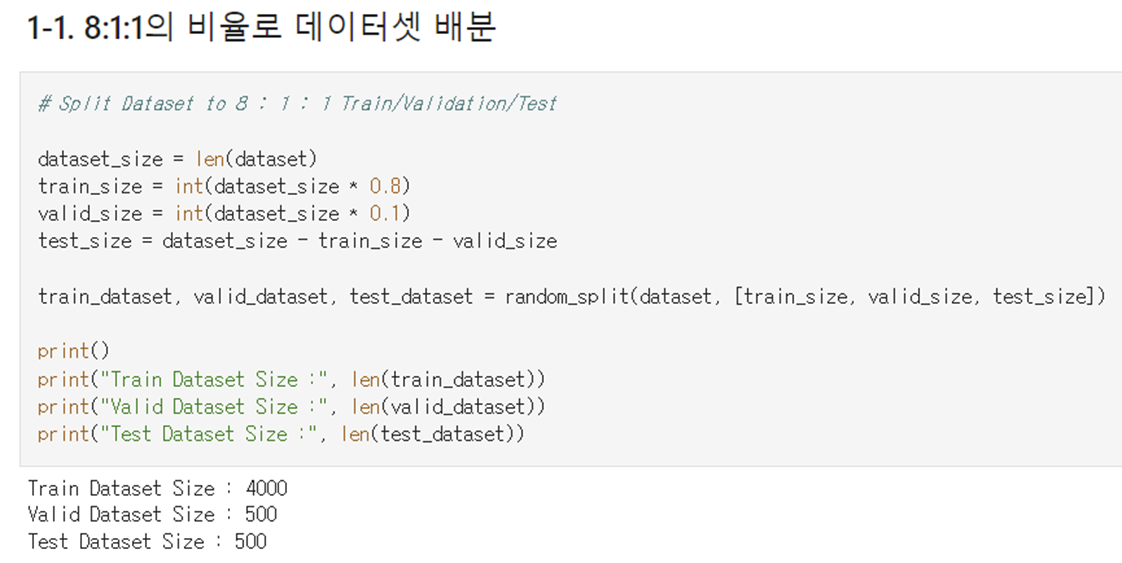
분리한 데이터셋은 아래 코드로 8 : 1 : 1의 비율로 무작위 배분하였으며
그 결과 데이터셋의 크기는 각각 4000 : 500 : 500 이었다.
데이터 증강 기법에는 영상처리에서 흔히 다루는 필터링, 채널값 수정등의 기법과
Rotation, Crop, Flip등 영상에 대한 변환을 수행하는 기법들이 있다.


데이터셋을 과도하게 증강시키면 Test Accuracy가 낮아지고 모델이 Underfitting 되는 경우가 발생하기에
다음과 같이 영상의 핵심 Feature를 크게 벗어나지 않는 증강만 수행하도록 했다.
- Random Resized Crop (무작위 Crop 후 영상의 스케일 변경)
- Random Rotation (무작위 방향으로 회전)
- Random Horizontal Flip (무작위로 수평 반전)
PyTorch 환경에서 진행했기 때문에 Compose 함수를 이용해 증강 과정을 한 줄로 묶어서 진행했다.
증강 과정에서 각 영상의 채널별 평균값(Mean)과 표준편차(Std)를 이용해 영상을 정규화하고,
후에 데이터로더에 담아 사용할 수 있도록 Tensor 형태로 변경해주었다.

전이 학습(Transfer Learning)이란 다른 목적을 달성하는데 사용했던 신경망을 다른 데이터셋 또는
다른 문제에 적용시켜 해결하는 것을 의미한다.
쉽게 생각하면, Cpp를 배울때 C와 Java를 배우고 이해한 학생이 프로그래밍을 처음 배우는 학생보다
보편적으로 이해도나 학업 성취도적인 측면에서 나은 것과 유사하다고 볼 수 있다.
전이 학습에서는 기존의 다량의 데이터셋을 학습한 모델을 불러와 구성을 일부 수정하고 사용한다.

일반적으로 모델 학습에 있어 네트워크가 깊어짐에 따라 학습하는 Feature가 달라진다고 하는데,
자동차에 대한 영상을 학습하는 것을 예로 들어보자.
낮은 층에서 학습되는 Low-Level Feature는 자동차의 형상, 색 등의 큼직큼직한 Feature를 뜻하고
깊은 층에서 학습되는 High-Level Feature는 바퀴의 패턴, 전면부 형태등 최종적으로 분류하는데 있어
조금 더 디테일한 Feature를 의미한다고 볼 수 있다.
따라서 기존 모델의 구성에서 상대적으로 말단에 위치한 레이어들만 수정하면
기존의 가중치는 유지하면서 새로운 Classifier를 만들 수 있게 된다.
그럼 모델을 한번 구성해보자.
우선 사전학습 모델은 1000개 클래스에 대한 1000만개가 넘는 데이터셋인 ImageNet을 학습한
ResNet50 모델을 PyTorch에서 제공하는 API를 이용해 불러온다.
from torchivision import models
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = models.resnet50(pretrained=True).to(device)그리고 전이 학습 효율을 향상하기 위해 Layer Freezing 기법을 사용한다.
본인의 경우엔 60번째 가중치(약 16번째 레이어)까지는 가중치가 새로 학습되지 않도록 Freezing 해두고
그 뒤부터 50번째 레이어까지의 모든 가중치는 새로 학습될 수 있도록 뒀다.
count = 0
for param in model.parameters():
if count > 60:
break
param.requires_grad = False
count += 1이렇게 코드를 작성하면 60번째 가중치까지는 requires_grad 상태가 False가 되면서 새로운 기울기를 구하지 않고
기존의 가중치를 유지하게 된다.
마지막으로, 10개의 클래스에 대한 분류를 하기 위해 모델 마지막의 전연결 레이어를 수정했다.
num_features = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(num_features, 128),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(128, 10),
nn.LogSoftmax(dim=1)
)
model = model.to(device)모델이 마지막 레이어에서 전달하는 Feature의 차원을 선형 회귀를 이용해 줄이고
이를 ReLU 활성화 함수를 통해 1과 0으로 변환한다.
이렇게 변환된 Feature는 과적합을 방지하기 위해 Dropout 기법을 이용해 정규화하고
이 값은 최종 분류를 위해 10개의 차원으로 변환되며 각 클래스별 확률 분포를 얻기 위한
로그 함수 형태의 Softmax 함수를 추가한다.
동결을 해제하기 전에는 20 Epoch에서 학습 정확도가 약 80%에 수렴한 뒤 과적합이 시작됐지만
동결을 해제한 후에는 3 Epoch만에 좋은 Acc와 Loss에 도달했다.

Training Accuracy는 98.72%, Loss는 0.06에 도달했고
Validation Accuracy는 93.20%, Loss는 0.23에 도달했다.


이를 통해 Layer Freezing을 통한 Transfer Learning 기법이
학습 효율과 성능 향상에 큰 도움이 되는 것을 직접 확인할 수 있었다.
Batch Size를 64로 설정한 Test Dataset에 대한 성능 측정 결과
평균 정확도는 0.9279로 준수하게 측정되었다.

또한, 20장의 임의의 사진을 테스트하여 성능을 측정한 결과
20장 중 19장의 이미지에 대한 정확한 결과를 도출하여 약 95%의 정확도를 보였다.
