[ResNet] Deep Residual Learning for Image Recognition
ResNet은 Computer Vision의 CNN 모델들의 발전에 있어 중요한 한 획을 그은 모델이다.
지금이야 우리가 CNN 모델을 구성할 때 모델의 Complexity에 따른 Overfitting이나 Optimization을 걱정해야하지만,
당시에는 모델이 더 복잡해지더라도, 그러니까 모델의 Layer 개수가 늘더라도
성능 향상에 있어 뚜렷한 효과를 보기 힘들었다고 한다.
그러한 당시의 문제점을 해결한 모델이 바로 ResNet이다.
ResNet은 2015년에 논문으로 처음 세상으로 나왔다.
당시 최대의 성능을 보여주던 CNN 모델은 2014년에 개발된 GoogLeNet이었고, 이 모델의 Layer 개수는 22개에 불과했다.

그래도 GoogLeNet은 Inception이라고 불리는 신경망을 Propose함으로써 Computer Vision 분야에서
꽤 효율적인 구조를 도입한 혁신적인 모델이긴 했다. (이는 추후 자세하게 알아보자)
다시 본문으로 돌아와서, Layer 개수를 22개 밖에 구성하지 못한 이유는,
Layer가 깊어지면 깊어질수록 Gradient Vanishing/Exploding(기울기 소실 및 폭발) 문제가 발생했기 때문이었다.
이는 일반적으로 기울기를 구할 때 손실 함수의 미분값을 Back-Propagation(오차 역전파) 방법으로 구하는데,
이 과정에서 활성화 함수의 편미분을 구하고 그 값을 곱해줄때 Layer가 깊어지면 깊어질수록 미분값이 여러번 곱해져
0에 가까워지기 때문이다.

이 그래프는 20-Layer CNN 모델과 56-Layer CNN Model에 동일한 CIFAR-10 데이터셋을 학습시킬때,
학습이 진행될수록 변화되는 학습 오차를 보여주고 있다.
대충 봐도, 56-Layer CNN 모델이 Layer 깊이가 더 얕은 20-Layer CNN 모델보다
정확도가 적게는 2-30%, 많게는 50%까지도 낮은 것을 볼 수 있다.
ResNet은 Identity Mapping(항등 사상)이라는 기법을 사용하여 깊은 Layer에서 효율적인 학습이 가능하다고 주장했다.
ResNet의 핵심 아이디어는 바로 Residual Learning(잔차 학습)이었다.
아이디어 자체는 굉장히 간단하다. 하나의 레이어에 입력으로 들어가 결과가 되어 나온 출력값을
그 다음 레이어의 처리가 끝나고 나온 출력값에 더해주는 방법이다.
이를 조금 더 직관적으로 설명하면, 기존의 신경망에서는 H(x) = x로 학습을 진행했지만
ResNet 아키텍쳐에서는 H(x) = F(x) + x로 학습을 시킨다.
이렇게 학습을 시키게 되면 앞서 말한 기울기가 0에 가까워지는 기울기 소실 문제가 발생하더라도,
H(x) = 0 + x가 되기 때문에 기울기 소실 문제를 해결할 수 있게 되는 것이다.
기울기 소실 문제를 해결하면, 레이어의 Depth와는 상관없이 깊은 Layer에서도
효율적인 학습이 가능하다는 것이 ResNet의 핵심이다.

이러한 구조는 최적화하기가 기존 모델들보다 편하고, Layer가 늘어나더라도 모델의 Parameter 수에 영향을 주지 않아
연산량 증가가 없으며, 단순히 입력에서 출력으로 연결되는 Shortcut 구조만 구현하면 되기 때문에
기존 프레임워크에서도 구현이 쉽다는 장점이 있었다.
실제로 이를 통해 152개의 레이어를 쌓는데 성공하면서 기존의 GoogLeNet보다 더 나은 성능을 보였고,
실험적으로는 1000개 이상의 Layer를 쌓아도 문제가 없었다고 한다.
이렇게 할 수 있었던 기본적인 가정은, 우리가 현실을 복잡한 함수라고 생각할 때
우리의 모델은 다수의 Non-Linear(비선형) Layer가 쌓여져 있는 형태라고 할 수 있고
이런 다수의 비선형 레이어가 복잡한 함수를 점근적으로 근사시킬 수 있다면
그것의 잔차함수, 즉 H(x) - x도 무의식적으로 근사시킬 수 있다는 것이다.
쉽게 말하면, 잔차함수도 결국 기존의 함수에서 파생된것이기 때문에 이것만 이항시킨 형태는
쉽게 근사가 가능하다는 이야기다.
하지만 이러한 Residual Connection을 진행할때, 문제가 하나 발생한다.
Tensor 형태의 출력 영상의 차원과 입력 영상의 차원이 달라 단순히 더해주지는 못한다는 것이다.
Residual Learning에서 레이어를 하나 거칠때마다 Output의 차원이 하나씩 증가하니
두 Matrix를 그냥 더해줄수는 없다. 따라서 ResNet에서는 다음과 같은 2가지 해결책을 제시했다.
1. Zero Padding을 통한 차원 늘리기
2. Linear Projection을 통한 차원 늘리기

Zero Padding 기법을 활용하면 영상의 가장자리에 의미없는 값들을 배치하여 강제로 차원을 늘릴 수 있으며,
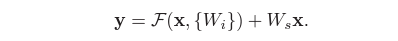
Linear Projection을 활용하면 가중치 Wi와 Identity Mapping을 곱하여 덧셈이 가능한 차원으로 만들어 줄 수 있다.
이러한 해결방법들로 출력 영상에 대한 Down Sampling을 각 Pooling Layer에서 수행해 Residual Connection을
성공적으로 구현했다.
다음으로 ResNet에서 가장 중요한 구조는, Bottleneck Architecture이다.
일반적으로 모델의 학습에 있어 레이어가 깊어질수록 Parameter는 기하급수적으로 늘어난다.
따라서 ResNet에서는 이를 감당하기 위해 각 Layer의 전/후에 1 x 1 크기의 Convolution Layer를
넣었고, 이렇게 앞뒤로 쌓인 1 x 1 Convolution Layer는 자체적으로 강제로 차원을 조절하며
다음 레이어의 입력에 필수적인 파라미터만 남겨두는 방식으로 파라미터를 효율적으로 줄이며 사용했다.
이 모양이 마치 병목과 같다고 하여 저렇게 지칭한다고 한다.

이러한 방법으로 성능도 좋고 연산량은 적은 ResNet-152 (ResNet-숫자에서 숫자는 레이어 수를 의미)를 만들어냈다.
이론상 더 깊은 Layer를 가진 모델도 구현이 가능하지만 효율적인 측면에서 그렇게 좋지는 않아 152까지만 사용한다.
이렇게 탄생한 ResNet과 Non-Residual 구조의 Plain ImageNet을 동일한 하이퍼 파라미터로 학습시킨 결과
Residual Architecture의 강력함이 증명되었다.

Plain 구조의 ImageNet은 Layer의 개수와 성능 사이에 큰 상관관계가 없었지만,
ResNet에서는 Layer가 깊어질수록 성능이 더 좋아지는 것을 확인할 수 있었다.
이렇게 ResNet은 간단한지만 아무도 생각해내지 못했던 아이디어를 구현해냄으로써
현재의 CNN 모델들 대부분의 근간이 되었다.