![[BeautifulSoup4] 국내 KOSPI/KOSDAQ 주식 종목 데이터 수집](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbgB6Sb%2FbtrWhtL8Ddy%2FOvxteep02QkpdS2LYFD9Mk%2Fimg.png)
외주 관련해서는 첫 글이다.
대학생 신분으로 이런 저런 알바도 다 해봤는데 제일 편한건 역시 전공 살려서 컴퓨터로 돈 버는거였다.
그래서 각종 외주 플랫폼이나 개인적인 루트로 솔루션 소프트웨어 개발 외주를 하고 있다.
그래도 어디 중소기업 신입 월급만큼은 꾸준히 나와줘서 생활비에 큰 보탬이 되고 있는데
블로그도 개설했으니 여태껏 했던 외주들도 꾸준히 하나씩 올려봐야겠다.

이번 외주는 국내 주식 시장의 KOSPI/KOSDAQ에 상장된 종목들을 자동 수집하는 프로그램을 개발하는 것이었다.
클라이언트분께서는 주식 거래를 부업으로 하시던분이셨는데, 하루에 6-7시간씩 직접 종목별 가격을 수집한다셨다.
솔직히 인터넷을 조금만 찾아보면 주식 종목을 수집해오는 프로그램을 쉽게 찾을 수 있는데,
사장님만의 데이터 정리 기준이 있으셔서 그것 때문에 직접 하시는 중이었다고 하셨다.
플랫폼에서 매칭되어 카페에서 미팅을 했고, 계약서 및 명세서 작성을 마치고 작업에 들어갔다.
요구하신 기능 구현은 다음과 같았다.
1. 기본적인 종목명, 코드, 업종, 가격등의 정보 수집
2. 240일 평균값을 계산하고 해당 평균값에 ±n%로 도달해가는지 확인 및 표시
2번의 구현이 특이하다면 조금 특이한 부분이었다.
기능 구현에서 크롤링이 꼭 필요했는데, Selenium을 사용할까 BeautifulSoup4를 사용할까 고민하다가,
비교적 간단한 크롤링이고 굳이 무거운 Selenium을 사용할 필요가 없을 것 같아 Bs4를 사용하기로 결정했다.
우선 크롤링할 사이트는 네이버 증권을 선호하셔서 네이버 증권 사이트로 결정했고 사이트 구성은 다음과 같았다.

네이버 증권사 페이지는 https://finance.naver.com/item/sise.naver 의 Base URL에
?code= 를 붙여 종목코드를 넣어서 각 종목을 살펴볼 수 있었다.
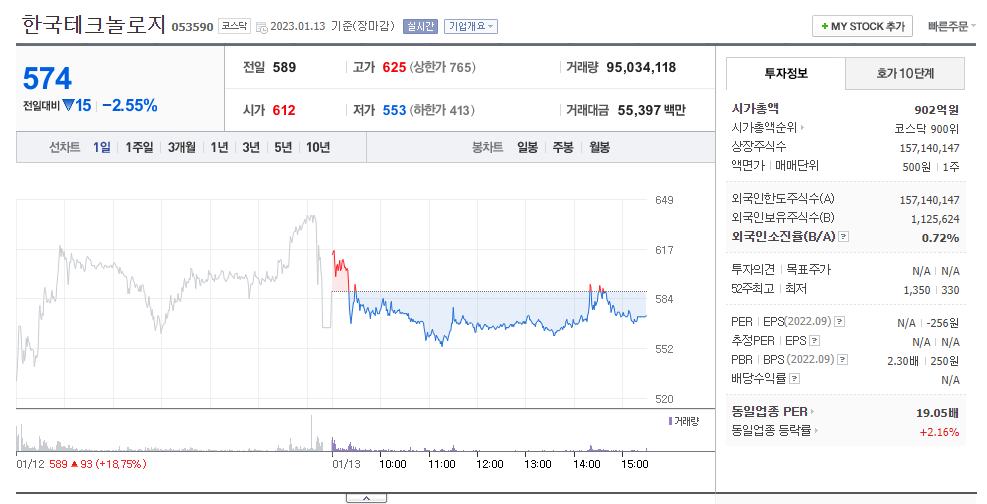
예시로 053590이라는 종목코드를 넣어 이동하면 다음과 같은 페이지로 접속할 수 있다.
그럼 여기서는 현재가 | 시가 | 종가 | 등락률 | 거래량 등의 정보를 바로 얻을 수 있다.
작성한 코드는 다음과 같다.
def value_return(code):
code = str(code)
if len(code) < 6: # 0으로 시작하는 종목코드 처리
code = str('0' * (6 - len(code)) + code)
url = 'https://finance.naver.com/item/sise.naver?code='
url = url + code
# 종류 | 종목명 | 종목코드 | 날짜 | 현재가 | 시가 | 종가 | 등락률 | 거래량 | 240일 평균
price_current = None # 현재가
price_start = None # 시가
price_end = None # 종가
rate = None # 등락률
volume = None # 거래량
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
price_current = soup.find('strong', {'id' : '_nowVal'})
if price_current is not None:
price_current = price_current.string
else:
price_current = '-'
price_start = soup.select_one('#content > div.section.inner_sub > div:nth-child(1) > table > tbody > tr:nth-child(4) > td:nth-child(4) > span')
if price_start is not None:
price_start = price_start.string
else:
price_start = '-'
price_end = soup.select_one('#content > div.section.inner_sub > div:nth-child(1) > table > tbody > tr:nth-child(3) > td:nth-child(4) > span')
if price_end is not None:
price_end = price_end.string
else:
price_end = '-'
rate = soup.find('strong', {'id' : '_rate'})
if rate is not None:
rate = rate.text.replace("\n", '').replace('\t', '')
else:
rate = '-'
volume = soup.select_one('#content > div.section.inner_sub > div:nth-child(1) > table > tbody > tr:nth-child(4) > td:nth-child(2) > span')
if volume is not None:
volume = volume.string
else:
volume = '-'
result = [price_current, price_start, price_end, rate, volume]
return result항상 크롤링을 하다보면 개발자 도구에서 Element를 하나씩 직접 찾아주는 과정이 너무 귀찮기도하고 하드 코딩이지만
어찌저찌 다 따오면 다음과 같이 코드를 작성할 수 있었다.
그럼 이제 큼직큼직한 데이터는 추출을 했고, 240일 평균값을 구해야하는데,
그러려면 240일치의 데이터를 모두 따와야한다.
하지만 우리의 친절한 네이버는 일별 시세를 제공해주는 별도의 페이지를 제공해주기에 이를 활용해보자.
다시 위에서 봤던 페이지로 이동하여 살짝 아래로 내려보면 일별 페이지가 테이블로 나와있다.
이 테이블을 개발자 도구로 검사해보면, 다음과 같은 iframe을 확인할 수 있다.

저 iframe에서는 해당 링크의 값을 불러와 보여주고 있는데, 우리는 저 링크를 활용한다.
https://finance.naver.com/item/sise_day.naver? 로 시작하는 URL에 code=종목코드를 넣어서
종목별 일별 시세를 확인할 수 있다.

그럼 이제 이 페이지에서 240일치 데이터를 크롤링 해오면 된다.
코드는 다음과 같다.
def GetAvg240(code):
url = "https://finance.naver.com/item/sise_day.naver?"
valueList = []
for i in range(0, 27):
pageUrl = url + "code=" + code + '&page=' + str(i + 1)
data = requests.get(pageUrl, headers={'User-agent': 'Mozilla/5.0'}).text
soup = BeautifulSoup(data, 'html.parser')
for index in range(2, 7):
span = soup.find_all('table')[0].find_all('tr')[index].find_all('td')[1].find('span')
if span is not None:
span = span.string
else:
continue
span = span.replace(",", '')
span = int(span)
if span is None:
continue
valueList.append(span)
for index in range(11, 15):
span = soup.find_all('table')[0].find_all('tr')[index].find_all('td')[1].find('span')
if span is not None:
span = span.string
else:
continue
span = span.replace(",", '')
span = int(span)
if span is None:
continue
valueList.append(span)
if (len(valueList) > 239):
valueList = valueList[0:239]
result = int(sum(valueList) / len(valueList))
return result페이지를 반복문으로 순회하며 넘어가고, valueList에 테이블에서 값을 하나씩 따와 넣어준 뒤
valueList의 길이가 240에 딱 맞도록 잘라준다.
그렇게 만든 리스트의 평균을 구해주고 리턴해주면 240일 평균을 구할 수 있다.
첫 번째 반복문 범위를 27로 해준게 이유가 있었는데 기억이 나질 않는다.. 일단 넘어가도록 하자.
다음으로 240일 평균값에 도달했는지 여부를 확인하는 코드를 작성한다.
def isNear(value_current, value_average):
# +- 10퍼센트로 설정
value_current = value_current.replace(",", '')
value_current = int(value_current)
value_average = int(value_average)
minus_range = value_average * 0.9
plus_range = value_average * 1.1
if (value_current > minus_range) and (value_current < plus_range):
return True
else:
return False생각보다 간단한데, 현재가와 240일 평균가를 인자로 전달받고 지정한 범위안에 들면 True, 벗어나면 False를 반환한다.
이러면 이제 기능적인 함수들은 구현이 끝났다.
별도의 엑셀 파일로 확인해볼 수 있도록 CSV 포맷으로 파싱하는 코드를 작성했고 결과 화면은 다음과 같다.

https://github.com/ssam2s/KOR-StockDataCollector/blob/main/new.py
GitHub - ssam2s/KOR-StockDataCollector: BeautifulSoup4 기반 국내 KOSPI/KOSDAQ 주식 종목 데이터 수집 및 전처리
BeautifulSoup4 기반 국내 KOSPI/KOSDAQ 주식 종목 데이터 수집 및 전처리 프로그램 (Comission) - GitHub - ssam2s/KOR-StockDataCollector: BeautifulSoup4 기반 국내 KOSPI/KOSDAQ 주식 종목 데이터 수집 및 전처리 프로그램 (C
github.com
자세한 코드는 내 Github에서 확인해볼 수 있다.

오랜만에 좋은 클라이언트 만나 깔끔하게 해결한것 같다.
'Commision' 카테고리의 다른 글
| [Python3] Win32 API를 이용한 PC 카카오톡 자동화 (0) | 2023.01.18 |
|---|